Overview
 This tutorial will show you different approaches when required to identify if two data sets are the same or, if not, which data rows are different. Some example scenarios where you would need this comparison: source versions (not managed in dedicated systems like CVS, SVN), new versus old version of external files which should be imported into an application (as to spot the differences), data from two tables from different databases (not linked to each other).
This tutorial will show you different approaches when required to identify if two data sets are the same or, if not, which data rows are different. Some example scenarios where you would need this comparison: source versions (not managed in dedicated systems like CVS, SVN), new versus old version of external files which should be imported into an application (as to spot the differences), data from two tables from different databases (not linked to each other).The approach is to think outside the box and use any kind of useful tool which helps with a quick solution. Usually, the solutions should be quick enough as not to interfere with the daily task activity. I propose for you three engines that I have used successfully with many occasions: Excel, an advanced text editor, a database engine.
Compare using Excel
Due to the fact that each row has multiple columns which should be compared, we will need a formula which will involve all columns for comparison. As a intermediary step, we create a new column with the concatenation of all column values for any row; this will create for us an useful column uniquely and exactly identifying the row data (this column I have called "derived full key"). Then, using Excel formula vlookup(), we search for the matching of the full key into the other data set ("search for match" column). Finally, using Excel formula isna,() and if(), we create proper text descriptions of our matching result ("improved version" column).Download the Excel file or check the following picture.
 |
| Click for full size picture |
Compare using an advanced text editor
Many modern text editors may be accompanied by a complementary comparison tool. One of these is Notepad++ installed with the Compare plugin (which may be also installed from the Notepad++ built-in plugin manager menu).Once you open both text files, you can activate the compare feature from the menu, then simply check one by one the reported differences (extra rows, missing rows, different data in similar rows, data which is the same but appears in different places in the text files).
 |
| Click for full size picture |
Compare using a database engine
For this example, I have used Oracle database and Oracle SQL Developer (freeware) client software. First step is to insert the data to be compared in the database tables. You may either use "insert" statements or Oracle SQL*Loader. The simpler import, when suitable, is to use insert statements from Excel files. Once you have the data open in Excel, you can create the insert statement syntax by using concatenation from the data columns.
Download the Excel file or check the following picture. SQL file is also available for download.
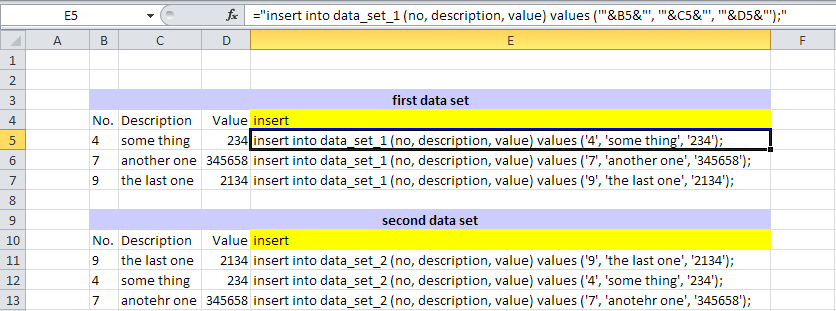 |
| Click for full picture size |
After you create the tables and insert the data, you can compare the data sets using a single SQL query; the first part selects the rows from one data set which do not exist in the second data set, and the second sql part does the same, but for opposite data sets:
(
select * from data_set_1
minus
select * from data_set_2
)
union
(
select * from data_set_2
minus
select * from data_set_1
)
select * from data_set_1
minus
select * from data_set_2
)
union
(
select * from data_set_2
minus
select * from data_set_1
)
Which method do you like best? Feel free to add other options from your experience.